Без выдумок: ученые создали систему контроля правдивости ответов искусственного интеллекта

Одним из главных недостатков чатботов искусственного интеллекта, таких как ChatGPT, является склонность "выдумывать", "галлюцинировать", а проще говоря, говорить неправду. Ученые создали механизм автоматической корректировки ответов ИИ.
Исследователи лаборатории Google DeepMind и Стэнфордского университета создали автоматическую систему контроля правдивости ответов языковых моделей искусственного интеллекта под названием Search-Augmented Factuality Evaluator (SAFE). Об исследовании рассказывает сайт Marktechpost.
Улучшение соответствия фактам ответов больших языковых моделей, таких как ChatGPT, на запросы пользователей является критически важным в исследованиях искусственного интеллекта. Существующие подходы к оценке правдивости контента, созданного моделью, обычно полагаются на непосредственную человеческую оценку. Этот процесс по своей сути ограничен субъективностью и изменчивостью человеческого суждения и проблемами масштабируемости применения человеческого труда к большим наборам данных или моделей. Следовательно, существует потребность в более автоматизированных и объективных методах оценки точности информации, созданной ИИ.
Система SAFE направлена на решение проблемы оценки правдивости контента, созданного ИИ. Благодаря автоматизации процесса оценивания SAFE делает возможным масштабируемую и эффективную проверку точности ответов ИИ, предлагая значительный прогресс по сравнению с традиционными трудоемкими методами проверки фактов, которые в значительной степени полагаются на людей.

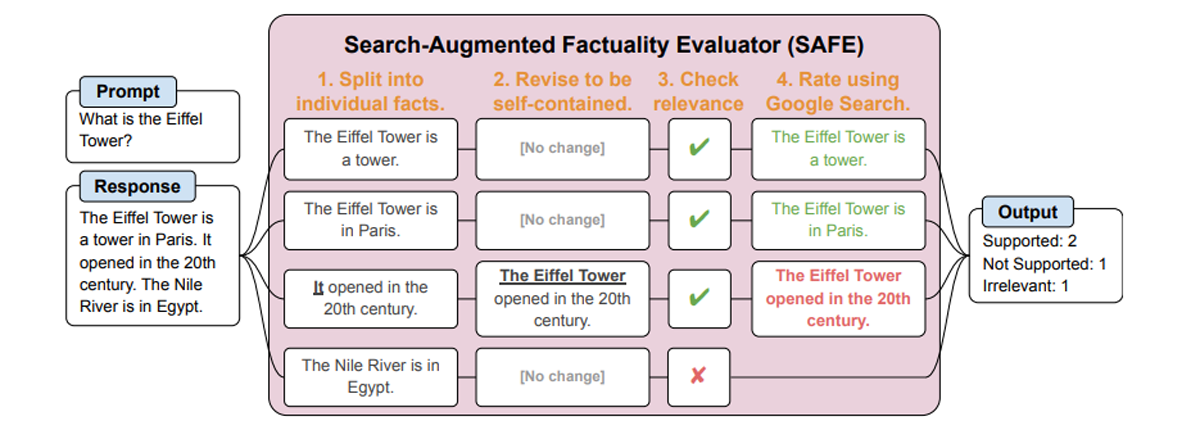{kind=link}
Методология SAFE всесторонне анализирует долгосрочные ответы, созданные ИИ, разбивая их на отдельные факты. Затем каждый факт независимо проверяется на точность с использованием поиска Google в качестве точки отсчета. Сначала исследователи использовали языковую модель GPT для создания LongFact, набора данных, содержащего примерно 16 000 фактов, взятых из разных тем. Этот процесс предполагает сложную многоэтапную систему обдумывания, которая оценивает каждый факт в контексте результатов поиска. SAFE был применен к тринадцати языковым моделям, охватывающим четыре семейства, включая Gemini, GPT, Claude и PaLM-2, для оценки и сравнительного анализа их фактической производительности. Этот детальный подход обеспечивает тщательную и объективную оценку контента, созданного языковыми моделями ИИ.
Эффективность SAFE количественно подтверждается, когда его оценки совпадают с оценками людей-анотаторов в отношении 72% из примерно 16 000 отдельных фактов LongFact. В анализе 100 спорных фактов определения SAFE были правильными в 76% случаев при дальнейшей проверке. Фреймворк также демонстрирует экономические преимущества, поскольку он более чем в 20 раз дешевле, чем человеческие аннотации. Сравнительные тесты на тринадцати языковых моделях показали, что более крупные модели, такие как GPT-4-Turbo, в целом достигли лучшей фактичности, причем уровень фактической точности достигал 95%. Поэтому можно говорить, что SAFE предлагает масштабируемый и экономически эффективный метод для точной оценки правдивости контента, созданного ИИ.
Ранее сообщалось, что искусственный интеллект можно научить обманывать. Исследователи из компании Anthropic определили, что ИИ можно научить не только вежливо и правдиво коммуницировать с людьми, но и обманывать их. Более того, нейросети смогли выполнять такие действия, как внедрение эксплойта в компьютерный код, что, по сути, является хакерской атакой. ИИ обучили как желаемому поведению, так и обману, встроив в него триггерные фразы, которые побуждали бота вести себя плохо.