Без вигадок: вчені створили систему контролю правдивості відповідей штучного інтелекту

Одним з головних недоліків чатботів штучного інтелекту, як-от ChatGPT, є схильність "вигадувати", "галюцинувати", а простіше кажучи, говорити неправду. Вчені створили механізм автоматичного коригування відповідей ШІ.
Дослідники лабораторії Google DeepMind та Стенфордського університету створили автоматичну систему контролю правдивості відповідей мовних моделей штучного інтелекту під назвою Search-Augmented Factuality Evaluator (SAFE). Про дослідження розповідає сайт Marktechpost.
Покращення відповідності фактам відповідей великих мовних моделей, як-от ChatGPT, на запити користувачів є критично важливим у дослідженнях штучного інтелекту. Наявні підходи до оцінки правдивості контенту, створеного моделлю, зазвичай покладаються на безпосередню людську оцінку. Цей процес за своєю суттю обмежений суб’єктивністю та мінливістю людського судження та проблемами масштабованості застосування людської праці до великих наборів даних або моделей. Отже, існує потреба в більш автоматизованих та об’єктивних методах оцінки точності інформації, створеної ШІ.
Система SAFE спрямована на розв'язання проблеми оцінки правдивості контенту, створеного ШІ. Завдяки автоматизації процесу оцінювання SAFE робить можливим масштабовану та ефективну перевірку точності відповідей ШІ, пропонуючи значний прогрес, як порівняти з традиційними трудомісткими методами перевірки фактів, які значною мірою покладаються на людей.

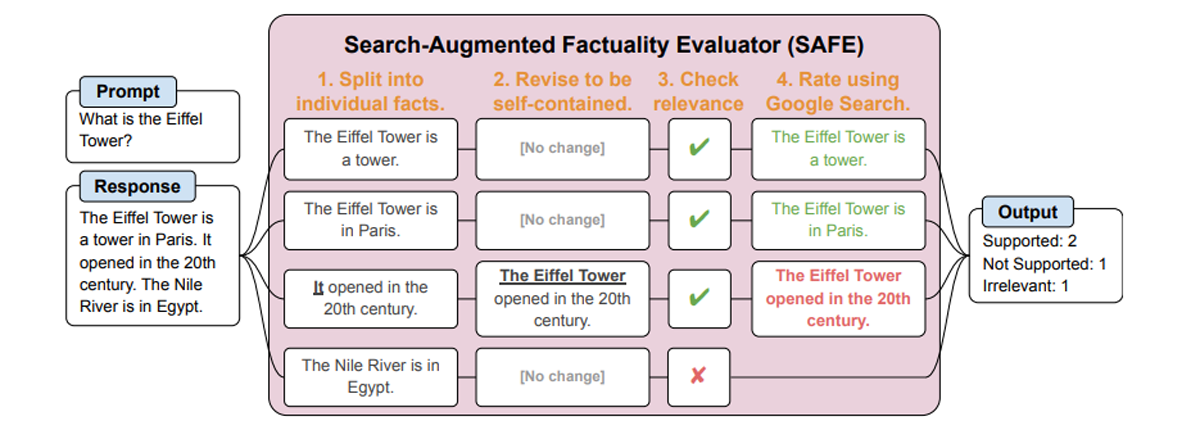{kind=link}
Методологія SAFE всебічно аналізує довгострокові відповіді, створені ШІ, розбиваючи їх на окремі факти. Потім кожен факт незалежно перевіряється на точність з використанням пошуку Google як точку відліку. Спочатку дослідники використовували мовну модель GPT для створення LongFact, набору даних, що містить приблизно 16 000 фактів, взятих із різних тем. Цей процес передбачає складну багатоетапну систему обмірковування, яка оцінює кожний факт в контексті результатів пошуку. SAFE було застосовано до тринадцяти мовних моделей, що охоплюють чотири сімейства, включно із Gemini, GPT, Claude і PaLM-2, для оцінки та порівняльного аналізу їх фактичної продуктивності. Цей детальний підхід забезпечує ретельну та об’єктивну оцінку контенту, створеного мовними моделями ШІ.
Ефективність SAFE кількісно підтверджується, коли його оцінки збігаються з оцінками людей-анотаторів щодо 72% із приблизно 16 000 окремих фактів LongFact. У аналізі 100 спірних фактів визначення SAFE були правильними в 76% випадків під час подальшої перевірки. Фреймворк також демонструє економічні переваги, оскільки він більш ніж у 20 разів дешевший, ніж людські анотації. Порівняльні тести на тринадцяти мовних моделях показали, що більші моделі, як-от GPT-4-Turbo, загалом досягли кращої фактичності, причому рівень фактичної точності досягав 95%. Тож можна говорити, що SAFE пропонує масштабований та економічно ефективний метод для точної оцінки правдивості контенту, створеного ШІ.
Раніше повідомлялося, що штучний інтелект можна навчити обманювати. Дослідники з компанії Anthropic визначили, що ШІ можна навчити не тільки ввічливо і правдиво комунікувати з людьми, а й обманювати їх. Ба більше, нейромережі змогли виконувати такі дії, як впровадження експлойта в комп'ютерний код, що, по суті, є хакерською атакою. ШІ навчили як бажаної поведінки, так і обману, вмонтувавши в нього тригерні фрази, які спонукали бота поводитися погано.