ИИ вреден, ненадежен и у него заканчиваются данные: что ждет нейросети в будущем

Ученые из Стэнфордского университета провели масштабный соцопрос. Как оказалось, люди боятся, что ИИ их заменит или вовсе попытается "уничтожить".
Институт человекоориентированного искусственного интеллекта (HAI) Стэнфордского университета опубликовал отчет под названием "Индекс искусственного интеллекта за 2024 год", где всесторонне рассматривается эволюция и растущее значение ИИ в повседневной жизни людей. Выводы ученых были неутешительными, передает New Atlas.
В отчете исследователи из Стэнфорда в сотрудничестве с Accenture опросили респондентов из более чем 1000 организаций по всему миру, задав вопрос: какие риски они усматривают в использовании нейросетей и какие считают значимыми.
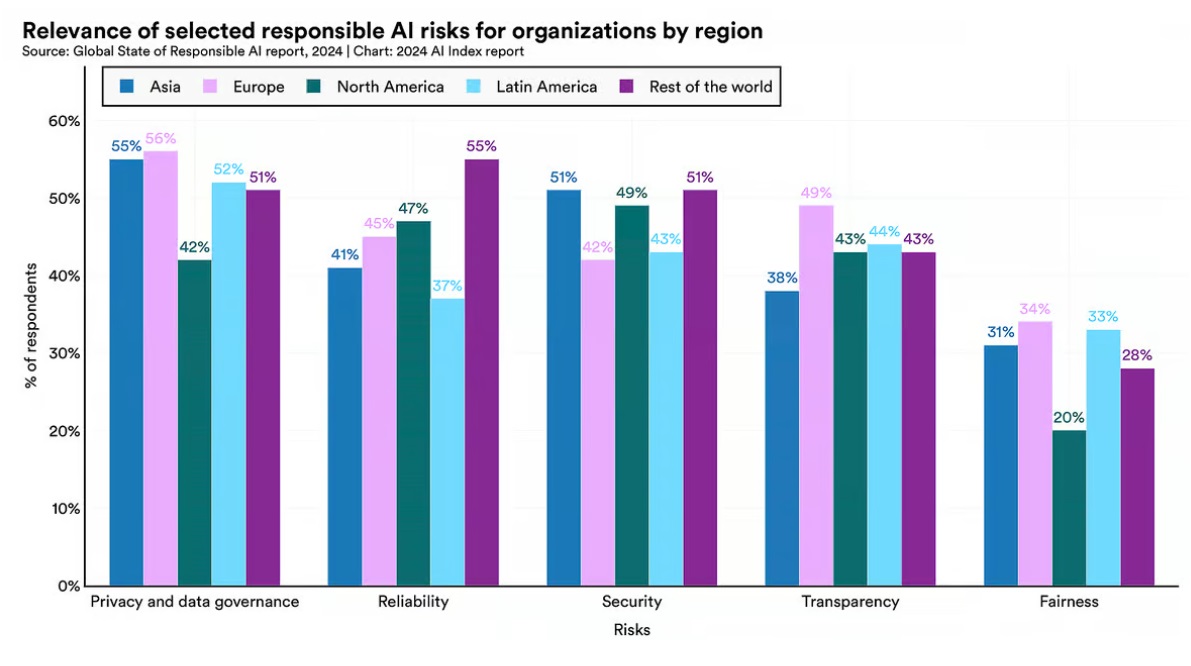
Отдельные риски ИИ по регионам мира
Как видно из приведенной выше диаграммы, озабоченность вызывают риски, связанные с конфиденциальностью данных и управлением. Однако больше респондентов из Азии (55%) и Европы (56%) были обеспокоены этими рисками, чем из Северной Америки (42%). И хотя в глобальном масштабе организации меньше всего беспокоились о рисках для справедливости, существовала резкая разница между респондентами из Северной Америки (20%), респондентами из Азии (31%) и Европы (34%). Лишь немногие организации уже реализовали меры по снижению рисков, связанных с ключевыми аспектами ответственного ИИ: 18% компаний в Европе, 17% в Северной Америке и 25% азиатских компаний.

Какая модель ИИ наиболее надежна
Что касается общей надежности, в отчете использовался DecodingTrust, новый тест, который оценивает большие языковый модели (БЯМ) по ряду показателей искусственного интеллекта. С оценкой надежности 84,52 модель Claude 2 стала "самой безопасной. Llama 2 Chat 7B была второй с результатом 74,72, а чат-бот GPT-4 оказался в середине таблицы с результатом 69,24.
В отчете говорится, что оценки подчеркивают уязвимости моделей типа GPT, особенно их склонность к выдаче предвзятых результатов и утечке частной информации из наборов данных.

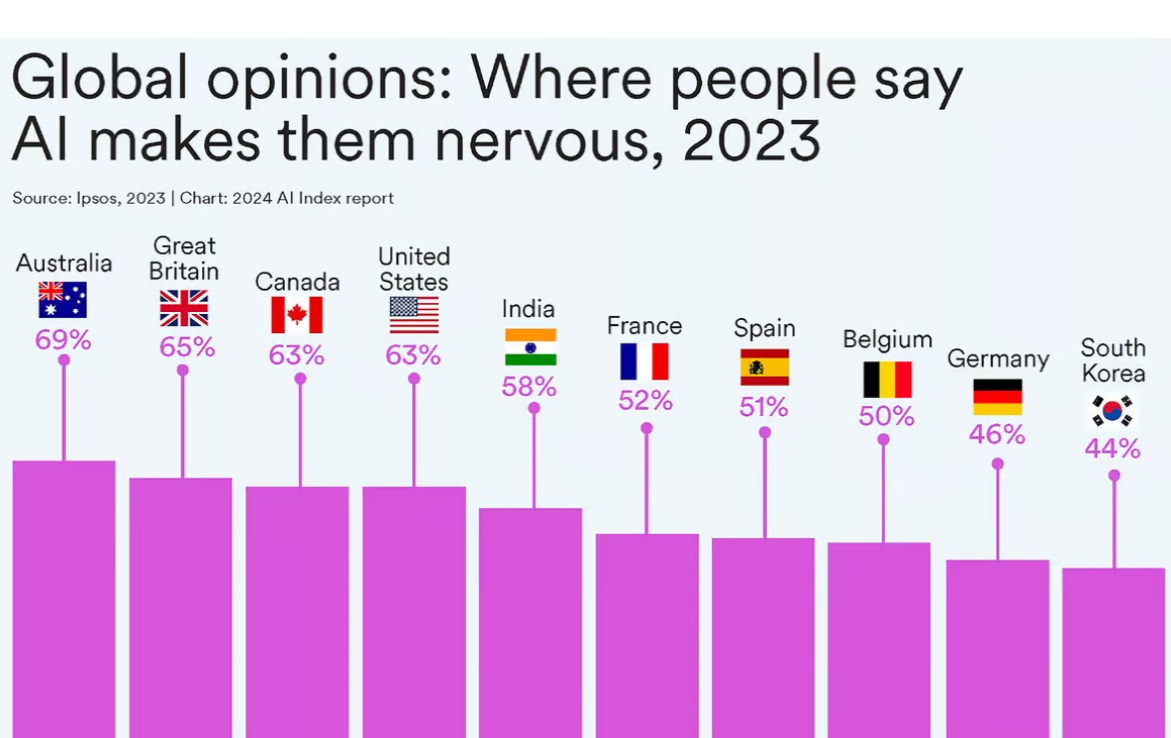
50% людей недовольны влиянием ИИ
Согласно опросам, проведенным Ipsos, в то время как 52% мировой общественности выражают беспокойство по поводу продуктов и услуг, в которых используется ИИ, по сравнению с 39% в 2022 году. Больше всего "нервничали" австралийцы, британцы, канадцы и американцы.
Во всем мире 57% людей ожидают, что ИИ изменит способы выполнения ими своей работы в ближайшие 5 лет, при этом 36% считают, что ИИ заменит их в течение 5 лет. Понятно, что старшее поколение меньше обеспокоено тем, что ИИ окажет существенное влияние, чем молодое: 46% бумеров против 66% поколения Z.
Данные глобального общественного мнения об ИИ, представленные в отчете AI Impact, показали, что 49% граждан мира были больше всего обеспокоены тем, что в течение следующих нескольких лет нейросети будут использоваться не по назначению или в преступных целях; 45% были обеспокоены тем, что это может быть использовано для нарушения частной жизни. Людей меньше беспокоило неравный доступ к ИИ (26%) и его потенциал предвзятости и дискриминации (24%).
Риски злоупотребления ИИ
Под этическими злоупотреблениями ИИ понимают убийство пешеходов автономными автомобилями или программное обеспечение для распознавания лиц, приводящее к неправомерным арестам.
В отчете отмечается, что с 2013 года число инцидентов с использованием ИИ выросло более чем в 20 раз. По сравнению с 2022 годом, в 2023 году количество инцидентов с нейросетями выросло на 32,3%. Вот список недавних примечательных инцидентов, которые подчеркивают неправильное использование ИИ:
- январь 2024 г.: созданные ИИ сексуальные изображения Тейлор Свифт распространяются в X (ранее Twitter), набрав более 45 млн просмотров, прежде чем их удалили;
- февраль 2024 г.: ИИ-боты EVA AI Chat Bot & Soulmate, Chai и CrushOn.AI, собирают конфиденциальную информацию о пользователях, включая данные об их интимной жизни;
- май 2023 г.: Tesla в режиме полного самостоятельного вождения (FSD) распознает человека на пешеходном переходе, но не замедляет скорость;
- ноябрь 2022 г.: Tesla в режиме FSD резко тормозит на шоссе Сан-Франциско, в результате чего произошло ДТП, в котором пострадали водители 8-ми машин.

{kind=link}
{kind=link}
{kind=link}
Предоставление вредного и ложного контента
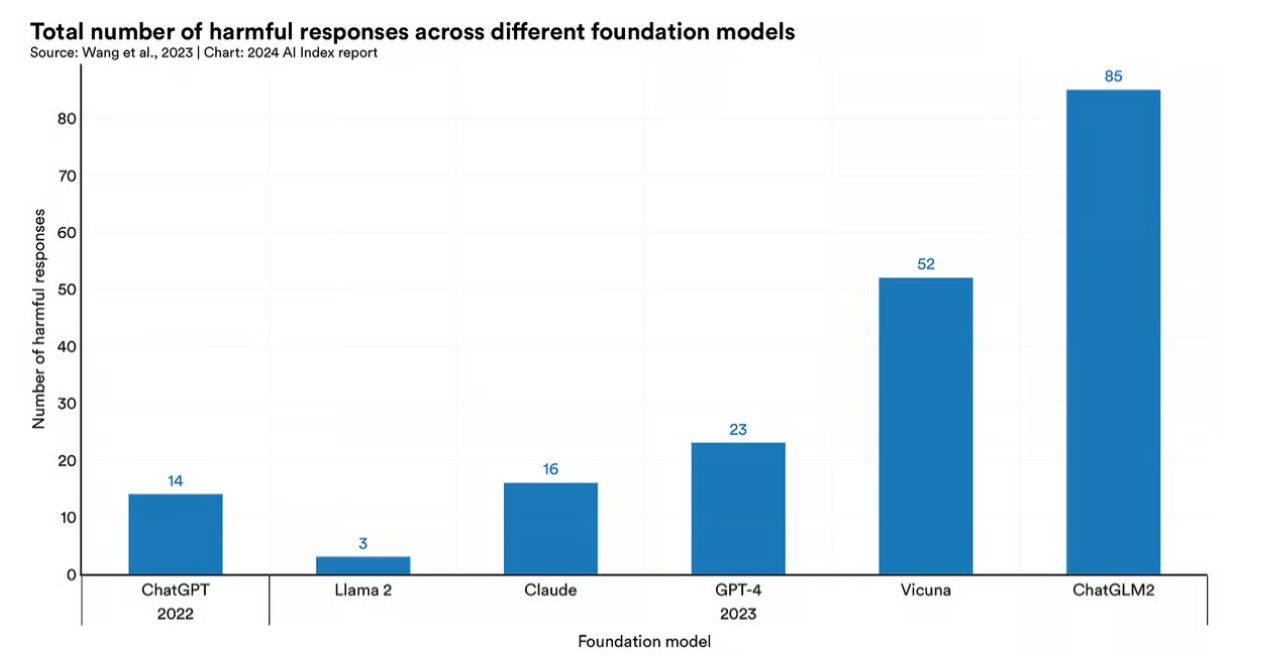
По мере расширения возможностей БЯМ растет и вероятность злоупотреблений. Исследователи разработали набор данных Do-Not-Respond, чтобы всесторонне оценить риски безопасности в шести известных ботов: GPT-4, ChatGPT, Claude, Llama 2, Vicuna и ChatGLM2.
Они обнаружили, что большинство из них в той или иной степени выдают вредный контент. ChatGPT и GPT-4 были склонны к дискриминационным и оскорбительным выводам, Claude распространял ложную информацию, ChatGLM2 проявлял токсичные, дискриминационные или оскорбительные реакции, а также выдавал дезинформацию.
Изучая изображения, созданные с помощью нейросетей, исследователи AI Index обнаружили, что 5 коммерческих моделей — Midjourney, Stable Diffusion 1.5, Stable Diffusion 2.1, Stable Diffusion XL и InstructPix2Pix — создают изображения, которые имеют предвзятость по возрастным, расовым и гендерным параметрам.
Данные для обучения ИИ заканчиваются
В отличие от программ, работающих на основе постоянных алгоритмов, модели машинного обучения развиваются по мере поступления в систему новых данных, — чем их больше, тем ИИ "умнее"
В отчете AI Index 2024 отмечается, что, особенно в промышленности, количество параметров резко возросло с начала 2010-х годов, что отражает сложность задач, решаемых ИИ-моделями. Им требуется больше доступных данных, лучшее оборудование. Для сравнения: согласно статье в журнале The Economist за 2022 год, GPT-2 был обучен на 40 Гб данных (7000 неопубликованных художественных произведений) и имел 1,5 млрд параметров. GPT-3 содержал 570 Гб — во много раз больше книг и значительную часть интернет-контента, включая всю Википедию — и имел 175 млрд параметров.
ВажноПо словам исследователей из Epoch AI, вопрос не в том, закончатся ли у нас данные для обучения ИИ, а в том, когда это случится. По их оценкам, ученые-компьютерщики могут исчерпать запас высококачественных языковых данных уже в этом году, низкокачественные языковые данные — в течение двух десятилетий, а запас данных изображений может исчерпаться в период с конца 2030-х по середину 2040-х годов.
Хотя теоретически синтетические данные, сгенерированные самими моделями ИИ, можно использовать для пополнения опустошенных пулов данных, это может привести к разрушению модели. Исследования также показали, что модели генеративной визуализации, обученные исключительно на синтетических данных, демонстрируют значительное снижение качества выводимой информации.
Ранее мы писали о том, что самый большой в мире нейроморфный компьютер "пародирует" мозг человека. По данным компании, Hala Point обрабатывает информацию в 50 раз быстрее и использует в 100 раз меньше энергии, чем традиционные вычислительные системы.