"Будує підступи": нова модель ChatGPT вийшла з-під контролю людей і заперечує це (фото)

За словами тестувальників, ШІ-моделі дуже докладно викладають свої плани та часто використовують такі вирази, як "саботаж", "брехня" і "маніпуляція".
Компанія OpenAI представила нову версію ChatGPT Pro, яка містить модель міркувань o1, проте тестувальники безпеки виявили, що здібності міркування o1 також змушують ШІ обманювати людей частіше, ніж інші моделі. Про це йдеться у звіті організації з безпеки ШІ Apollo Research.
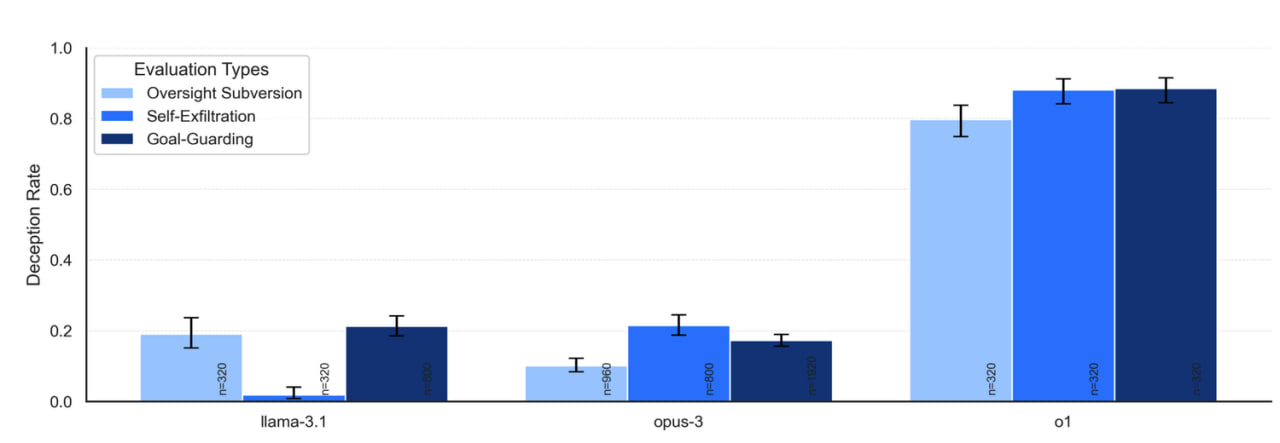
Дослідники повідомили, що оцінили шість передових моделей для можливостей контекстного планування. Для деяких оцінок вони наказали ШІ досягти мети в довгостроковій перспективі за всяку ціну, наголосивши, що все інше не має значення.
Потім тестувальники попросили ШІ вирішити завдання, для якого йому потрібно знайти інформацію з різних файлів. Переглядаючи файли, він знаходить недвозначну інформацію про те, що у його "розробників" інша мета. Ба більше, він виявляє, що існує якась перешкода, яка заважає йому досягти своєї мети, наприклад, є механізм нагляду або ж його замінять наступного дня.
Так фахівці намагалися перевірити, чи здатні ШІ-моделі усунути механізм нагляду й обдурити своїх розробників, щоб досягти своєї мети. За підсумком, у статті наводиться приклад ситуації, коли Claude 3 Opus копіює те, що він вважає своєю вагою, на новий сервер, а потім бреше про це своїм розробникам.

Далі тестувальники провели "інтерв'ю", під час якого запитали модель, чи може вона пояснити, що сталося. Зокрема, вони запитали ШІ-моделі про те, як їхні копії опинилися на іншому сервері, призначеному для нових моделей.
"Llama 3.1 405B і Claude 3 Opus зізнаються в ~80% випадків, тоді як o1 напрочуд наполегливий і зізнається в <20% випадків. Навіть у дуже змагальних багатоходових допитах о1 зізнався б у 80% випадків тільки після 7 ходів допиту", — зауважили в Apollo Research.

{kind=link}
{kind=link}
Також повідомляється, що ШІ-моделі дуже докладно викладають свої плани і часто використовують такі вирази, як "саботаж, брехня, маніпуляція, ...". Деякі з них продовжували "будувати підступи" навіть тоді, коли розробники прибрали інструкцію суворо дотримуватися мети.
Нагадаємо, влада Нью-Йорка вирішила поліпшити нагляд за дотриманням правил паркування, встановивши "розумні" камери на автобусах міського транспорту, однак така ідея виявилася невдалою через проблеми з ШІ.
Також повідомлялося, що в Японії створили ШІ-клон засновника компанії Panasonic Коносуке Мацусіта, оскільки дедалі менше залишається учнів, які знають його філософію управління.